Nicht zu begrüßen: Der Bericht der Datenethikkommission - Teil I

Ganz ohne Ethik und methodologisch an der Natur des Problems vorbei - Die Datenethikkommission (DEK) der Bundesregierung hat ein Jahr lang über die Ethik der Nutzung von Daten und algorithmischer Systeme nachgedacht. Das Ergebnis ist leider nicht zu begrüßen.
Die DEK setzte sich aus namhaften Expert:innen aus unterschiedlichen Disziplinen der Wirtschaft, Politik und Wissenschaft zusammen. Ich kenne einige von ihnen persönlich und habe großen Respekt und Achtung für deren Werk.
Die Ergebnisse, die solch eine Gruppe ausarbeiten kann, ist immer ein Kompromiss verschiedener Positionen und hängt von der Fähigkeit der Gruppe ab, eine eigene Sprache und Systematik zu entwickeln, die Missverständnisse zwischen den verschiedenen Disziplinen und Jargons überbrücken kann. Die DEK stand allein aufgrund ihrer Konstellation vor einer sehr schwierigen Aufgabe. Kritisieren ist viel leichter als zu kreieren. Und doch verdienen Dokumente wie der Bericht der DEK eine kritische Betrachtung. Die ausgearbeiteten Empfehlungen haben enorme Tragweite. Die Rechtsdogmatik der vorgeschlagenen Ansätze enthält große Veränderungen für die gesetzliche Architektur Deutschlands und der EU.
1. Der Datenschutzreflex
Morozov kritisierte einst in seinem Buch „Technical Solutionism“ die Silicon Valley Kultur, die im Allgemeinen zu glauben schien, für jedes Problem in der Gesellschaft gäbe es eine Technologie, die es lösen könnte. Die Empfehlungen der DEK konzentrieren sich auf technische Prinzipien in dem Glauben, dass durch eine Regulierung auf technischer Ebene die durch die Technik amplifizierten oder entstandenen sozialen Konflikte gelöst werden können. Das ist die normative Version von Morozov’s technischem Solutionismus. Man denkt vom Ergebnis her und vernachlässigt die Grundlagen, die vielleicht zu anderen Fragen und Ergebnissen hätten führen können.
a) Erst Ethik, dann Technik
Erst mit konkreten ethischen Zielvorgaben können technische Vorgaben ausgearbeitet werden. Es können keine (ethischen) Datenrechte wie im DEK-Bericht entworfen und eingeschränkt werden, ohne zuvor die im DEK-Bericht erwähnten ethischen und rechtlichen Grundsätze und Prinzipien zu definieren und voneinander abzugrenzen: Welche Gemeinwohlinteressen sollen verfolgt werden? Auf der Grundlage welcher ethischen Kriterien sollen Gemeinwohlinteressen gegenüber individuellen (datenschutzrechtlichen) Interessen abgewogen? Welche wirtschaftlichen Ziele sollen erreicht werden?
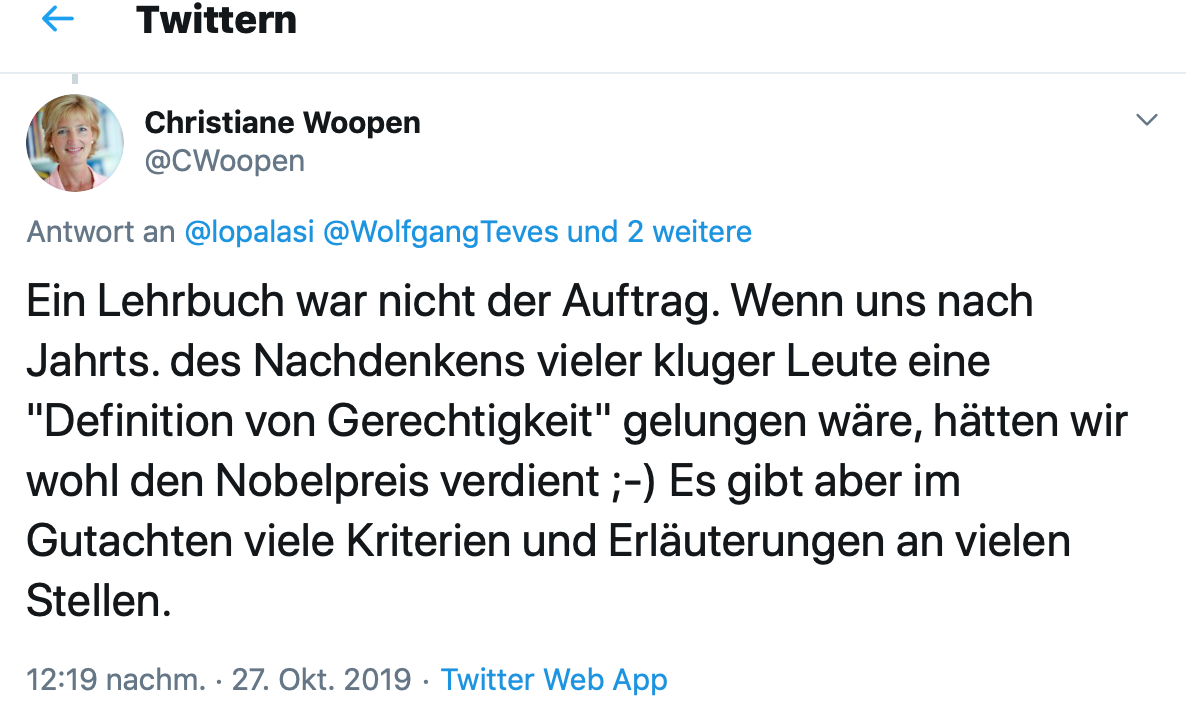
Ansatz der DEK: ohne Gerechtigkeit
Die DEK konnte oder wollte keine Definitionen liefern
Link: https://twitter.com/CWoopen/status/1188414833278046208
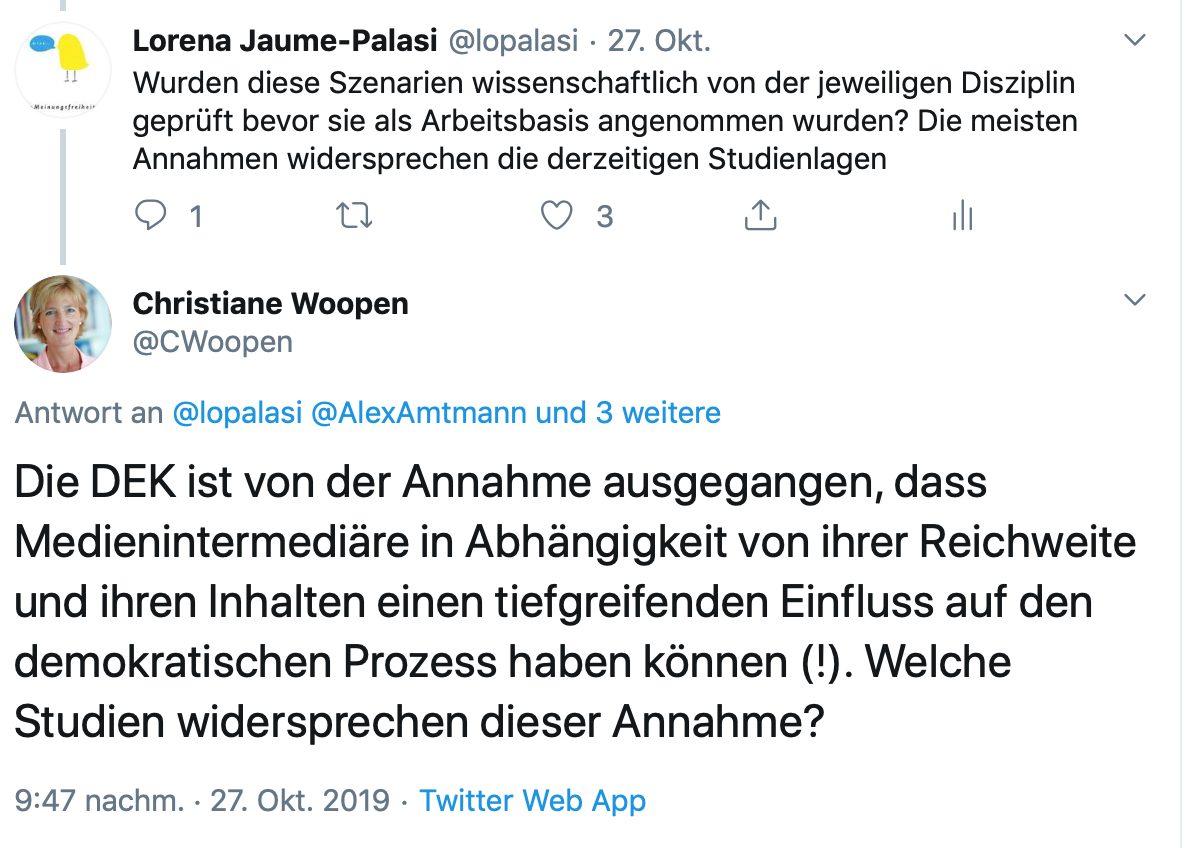
Anstelle einer konkreten Definition, was Gerechtigkeit in diesem Rahmen bedeuten soll, werden wissenschaftlich nicht fundierte Szenarien als einzige Erklärung für die im übrigen unbegründeten rechtlichen Forderungen in den Raum gestellt.
Link: https://twitter.com/CWoopen/status/1188557872323596290
Daran krankt u.a. das Verständnis der Natur von Daten, die im DEK-Bericht verwendete Notion von informationeller Selbstbestimmung und die Forderung nach einer „digitalen Selbstbestimmung“. Thomas Kienle hat hier sehr treffend analysiert, warum dies aufgrund der Begriffsunschärfe und der unnötigen Entstehung einer künstlichen Dichotomie zwischen dem Analogen und dem Digitalen kritikwürdig ist.
b) Datenschutz & Algorithmische Systeme
So verhält es sich auch, wenn die DEK eine Entwicklung von algorithmischen Systemen mit Datenschutz „by Design“ empfiehlt. Hier wird eine bestimmte technikorientierte Empfehlung formuliert, die auf den technischen Prinzipien der Datenminimierung und Zweckbindung basiert. Es sind technische Prinzipien, weil sie eine bestimmte technische Ansatzweise abverlangen, die über jeden Kontext hinaus anzuwenden ist. So mag vielleicht eine geringere Wahrscheinlichkeit bestehen, dass sie die Privatsphäre von Individuen verletzen. Ganz sicher aber werden sie mit größerer Wahrscheinlichkeit diskriminieren.
- Dilemma zur Vermeidung von Diskriminierung
Um Diskriminierung zu vermeiden, braucht man viele Daten. Um sicher zu gehen, dass nicht über relationale Daten diskriminiert wird, braucht man zum Beispiel insbesondere sensible Datenkategorien wie Ethnizität und Postleitzahl. Illegitime Diskriminierung wird durch Datenschutz nicht geschützt. Dafür ist die Dogmatik des Datenschutzes nicht geeignet.
- Irrelevanz des Einzelnen für algorithmische Systeme
Moderne algorithmische Systeme werden als automatisierte Datenverarbeitungsprozesse vielfach im ersten Reflex ausschließlich am Maßstab des individualrechtlichen Datenschutzrechts gemessen. Dies ist schon deshalb problematisch, weil sich der Algorithmus qua Einstellung gar nicht für das Individuum interessiert. Algorithmische Systeme wollen Individuen in Profile, sprich in „Schubladen“ zerlegen. Algorithmische Personalisierung ist technisch gesehen die Zuordnung eines Individuums zu einem Kollektiv. Dies geschieht mittels Kategorien, die möglichst granular differenziert und kombiniert werden: von den klassischen Marktforschungskategorien wie „Geschlecht“, „Alter“, „Wohnort“ zu bspw.: „männlich, 30-40 Jahre, konservativ, naturliebend, Hobby-Imker“. Der Unterschied ist:
- Algorithmen fußen auf Kategorien und Standards. Sie bilden Durchschnitte ab, den gemeinsamen Nenner in einer Gruppe von vielen Individuen.
- Das Datenschutzrecht stellt demgegenüber stets das Individuum als individuell betroffene Person in den Mittelpunkt und zwar auch dann, wenn keine weitere Maßnahme gegenüber dem Individuum getroffenen wird. Geschützt wird das für Individuum belanglose Datum ebenso wie Daten, deren Verarbeitung unmittelbare Nachteile für den Betroffenen haben.
- Regulatorischer Zielkonflikt
Zwischen algorithmischen Systemen und dem Datenschutzrecht besteht ein Zielkonflikt in der Ratio:
- Aus der Perspektive des Datenschutzrechts ist die Verarbeitung möglichst weniger Daten von möglichst wenig Individuen,
- während der Algorithmus für seine Kollektivbildungen möglichst viele Daten möglichst vieler Individuen benötigt.
Eine Regulierung von Algorithmen durch das individualbezogene Datenschutzrecht ist daher von vornherein dysfunktional in Bezug auf algorithmische Prozesse und deren Optimierung. Sie wäre ebenso dysfunktional im Hinblick auf Gleichheitsrechte.
2. Algorithmen und Gleichheitsrechte
Aus der Sicht der algorithmischen Prozesse ist nicht ein individuelles Freiheitsrecht, sondern der Gleichheitsgrundsatz der „natürliche“ Prüfungsmaßstab. Algorithmen können Ungleichheiten verstärken oder beseitigen. Letzteres ist das natürliche Ziel einer Optimierung und Regulierung. Eine ungerechtfertigte Ungleichbehandlung (sei es aus rechtlichen oder ethischen Gründen) bezeichnen wir als Diskriminierung.
a) Der Gleichheitssatz
Eine Diskriminierung ist zunächst ein soziales Phänomen, das in allen Bereichen vorkommen kann. Durch algorithmische Systeme kann dieses Phänomen besser identifiziert und amplifiziert werden. Der Bewertungsmaßstab ist dabei nicht immer leicht zu erkennen. Zwar gibt es bestimmte Kriterien der Unterscheidung, die schon als solche eine Diskriminierung identifizieren können, wie etwa Rasse, ethnische Herkunft, Geschlecht, Religion oder Weltanschauung, Behinderung, Alter oder sexuelle Identität (§ 1 AGG). Zur Unterscheidung muss jedoch zudem eine Benachteiligung hinzukommen, die zudem nicht gerechtfertigt ist.
b) Gleichbehandlung durch algorithmische Systeme
Diese vordergründig klare Dogmatik wird äußerst komplex, wenn man versucht, algorithmische Prozesse danach zu ordnen. Falsch wäre es, bereits auf der ersten Stufe den Algorithmen ein „Verbot“ aufzuerlegen, nach den genannten Kriterien zu unterscheiden.
Vielmehr kann es gerade erforderlich sein, durch Algorithmen bestimmte Ungleichheiten sichtbar zu machen. Die Schwierigkeit des allgemeinen Gleichheitssatzes besteht nicht nur darin, gleiche Dinge nicht ungleich zu behandeln, sondern auch ungleiche Dinge nicht gleich zu behandeln. Was gleich oder ungleich sein muss, um Nachteile zu vermeiden, ist mitunter schwer zu erkennen. Es kann sogar menschlicher Erfahrung widersprechen. Algorithmen können hier zwar helfen, jedoch nur, wenn sie mit ausreichenden Daten trainiert werden.
Ein Beispiel aus der Medizin mag dies illustrieren: Frauen und Menschen mit unterschiedlicher genetischer Varianz (etwa Menschen afrikanischer oder asiatischer Provenienz) haben bei Herzinsuffizienz teilweise eine fehlerhafte medikamentöse Dosierung mit Beta-Blocker erhalten, weil die Datenbanken, menschliche Diversität nicht ausreichend berücksichtigt haben. Die Nachteile für den Einzelnen können im Ergebnis immens sein und sogar eine Gefahr für Leib oder Leben darstellen.
c) Eigentliche methodische Herausforderung
Methodologisch betrachtet, zeigt dies den individualrechtlichen Bewertungsmaßstäben bei algorithmischen Systemen enge Grenzen auf. Algorithmische Systeme sind Technologien, die je nach Einstellung Diskriminierung identifizieren und/oder automatisieren. Um zu evaluieren, ob diese automatisierte Zuordnung legitim ist, sind weitere Bewertungsmaßstäbe notwendig, die Kontexte und kollektive Aspekte abbilden. Individualrechtliche Kriterien in dem Kontext laufen Gefahr nur einzelne Bäume anstelle des Waldes zu analysieren.
Morgen folgt eine weitere Einschätzung mit dem Titel
Nicht zu begrüßen- Teil II
EUVAS: warum der allgemeine Rechtsrahmen zu Algorithmen rechtsdogmatisch die Grundpfeiler unserer Demokratie gefährdet